Blogs
Van ChatGPT4 naar o1: De volgende stap in AI-evolutie
🧠💡 In de wereld van kunstmatige intelligentie volgen de ontwikkelingen elkaar razendsnel op. Toch zijn er momenten die eruit springen, momenten die een fundamentele ontwikkeling markeren. De recente aankondiging van OpenAI’s nieuwe model, o1, is zo’n moment. Wat maakt dit model zo bijzonder en waarom is dit een opmaak naar een nieuwe versnelling van de ontwikkelingen op ai-gebied?
Een nieuw paradigma
OpenAI, het bedrijf achter, heeft met o1 een grote stap voorwaarts gezet. Dit nieuwe model is niet zomaar een update; het vertegenwoordigt een nieuwe benadering van hoe AI-systemen informatie verwerken en problemen oplossen.
Het nieuwe aan o1 is de integratie van een ‘Chain of Thought’ (CoT) redeneerlaag. Deze laag stelt het systeem in staat om stapsgewijze redeneringen te maken. Deze aanpak stelt het systeem in staat om complexe, seriële problemen op te lossen. Seriële problemen zijn taken die stapsgewijs moeten worden opgelost, waarbij elke stap afhankelijk is van het resultaat van de vorige stap. Wiskunde, programmeren en wetenschap bedrijven zijn gebieden waar seriële problemen veel voorkomen. Taalmodellen als ChatGPT4 waren tot de komst van dit nieuwe model notoir slecht in het oplossen van dit soort problemen. (Voor een meer diepgaande verkenning van de mogelijkheden van CoT in generatieve ai-modellen, zie bv dit artikel [2402.12875] Chain of Thought Empowers Transformers to Solve Inherently Serial Problems (arxiv.org))
Momenteel zijn er twee varianten beschikbaar voor betalende gebruikers: o1-preview en o1-mini. Deze modellen zijn voorlopers van het volledige o1 model en draaien bovenop het GPT-4 model. NB. Er gingen al lang geruchten dat Openai aan deze techniek werkte, google maar eens op Q* / strawberry 😉.
Maar hoe werkt o1 precies? Het zijn eigenlijk 2 samenhangende veranderingen. De eerste verandering is de manier van het trainen van het model. Tijdens de training wordt het model systematisch beloond voor het maken van effectieve CoT-redeneringen. Oftewel die redeneringen die tot de gewenste oplossingen leiden. Hierdoor leert het welke redeneertechnieken het beste werken voor verschillende soorten problemen.
De tweede verandering is bij het concreet gebruiken van het model. Wanneer je nu o1 een complexe vraag stelt, past het deze geleerde technieken vanuit de training toe voordat het een antwoord geeft. Dit proces van het doorrekenen van een antwoord wordt inferentie genoemd. De inferentietijd was altijd heel erg kort, omdat het model direct overging tot een antwoord. Bij o1 duurt het krijgen van een antwoord soms wel 90 seconden. De inferentietijd is dus veel groter. Een kostbaar proces dat veel rekenkracht vergt. Het aantal prompts dat je mag draaien is dan ook nog erg beperkt. Vanaf vandaag 50 prompts per week voor o1-previes bv.
Schalingswetten
De reden waarom de taalmodellen als GPT4 steeds krachtiger worden, is tot nu toe verklaard met een zogenaamde schalingswet. Simpel gezegd wordt een taalmodel slimmer als je het model groter maakt en traint met meer (en betere) data. O1 introduceert nu een nieuwe dimensie aan deze schalingswet: hoe meer inferentie(training), hoe slimmer het model.
Deze nieuwe wet suggereert dat de intelligentie van een AI-systeem niet alleen afhangt van de hoeveelheid data of de grootte van het model, maar ook van zijn vermogen om te redeneren. Het model ‘kiest’ een redenering, test deze uit, en past deze aan naar eigen inzicht. Pas daarna komt het met een antwoord. Dit is een fundamenteel andere manier van werken dan we tot nu toe hebben gezien bij AI-systemen.
De resultaten van het minst beperkte model dat nu is uitgebracht (o1-preview) zijn al heel indrukwekkend. Ik heb zelf geen enkele programmeerervaring, maar heb met een paar prompts o1-previes voor me:
– een werkende schaakcomputer laten maken. Na 1 prompt werkte deze al in codepen.
– een onderwijsblendmodel ontwikkeld waarin docenten een leerweg kunnen visualiseren. Dit koste me 3 prompts.
NB. Dit zijn werkende voorbeelden, maar nog niet mooi genoeg en uitgewerkt genoeg. Het valt in de categorie testen en knutselen om te kijken wat de mogelijkheden zijn.
Ai in fasen
Om de vooruitgang in AI-ontwikkeling te duiden, heeft OpenAI een raamwerk ontworpen met vijf niveaus:
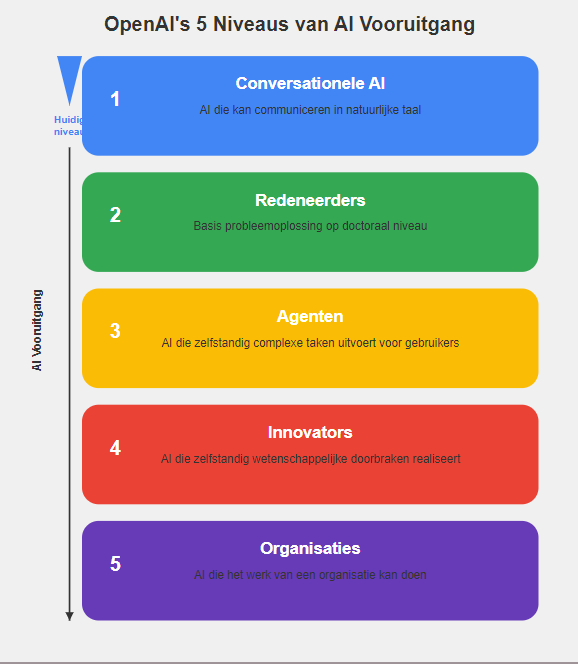
Met o1 maken we de sprong van niveau 1 naar niveau 2. We gaan van AI die kan converseren naar AI die kan redeneren. En hier wordt het echt interessant: de stap van niveau 2 naar niveau 3 kent weinig technische uitdagingen. Dit betekent dat de weg naar AI met echte ‘agency’ – het vermogen om zelfstandig complexe taken uit te voeren – nu open ligt. Stel je hierbij voor dat een bedrijf nu bv een software-engineer een opdracht geeft voor een complex project. De engineer werkt het uit en gaat aan de slag en komt een paar weken later met het eindproduct. Nu nog gebruikt deze engineer AI enkel voor alle tussenstappen, bv om code te schrijven of te verbeteren. Met Agency (paar jaar wachten nog?) gaat ai het hele project zelfstandig draaien, van A tot Z. Het gaat het project plannen, stap voor stap uitvoeren, tussentijds evalueren en levert vervolgens het gevraagde eindproduct op.
Relativering voor nu
Bovenstaande klinkt erg ingrijpend en dat gaat het mi ook zeker zijn. Maar: voor verreweg de meeste toepassing in het onderwijs heeft deze ontwikkeling geen of heel weinig rechtstreekse gevolgen. Een ai-tutor bv gaat nu niet direct slimmere antwoorden geven op vragen van een gemiddelde leerling. Dit geeft onderwijsinstellingen wat ademruimte om zich voor te bereiden op de komende veranderingen. Laten we dit nu dat ook eens doen, en ons niet weer laten overvallen door wat er aankomt!
🤔 Hoe zie jij de toekomst van AI in het onderwijs? Welke kansen en uitdagingen zie je met de komst van modellen zoals o1? Deel je gedachten in de comments!
#AI #Onderwijs #OpenAI #ToekomstVanLeren
P.S. Wil je meer weten over de integratie van AI in het onderwijs? Bezoek dan aivoordocenten.com, het platform dat ik samen met Tom Naberink heb opgezet om docenten te helpen bij het verantwoord implementeren van AI in hun lespraktijk.

